
pip 19.0 has been released on 22nd January 2019. On the feature list, most notably, it now supports PEP-517, which by
default is turned on when that the project has a pyproject.toml at the root folder. The PEP in question has been
created in 2015 and accepted in 2017. Even though it took a while until pip implemented it, the release and the issues
that followed confirmed that many people are not familiar with it. Read on if you want a picture of how the Python
packaging ecosystem evolved today and where we hope to see it down the line. The introduction of this python enhancement
proposal may cause some discomfort, but we will benefit from it in the long term.
I joined the Python open-source community around three years ago (though I have used it for more than 8 years). I’ve
remarked that the Python packaging has a reputation of a somewhat black box from the early days. There are many unknown
parts, and people mostly get by with just copying other projects, build configurations, and roll with them. On my path
to better understanding this black box and improving it, I’ve become the maintainer of both the virtualenv and tox
project, occasionally contributing to both setuptools and pip.
As I hope to give an exhausting (hopefully still a relatively high level) overview of the subject, I decided to split it
up into three posts. In this first post, I will give a broad overview of how Python packaging works and the type of
packages it has. In a subsequent post, I will present in detail how the installation of packages works and how
PEP-517/518 tries to improve on it. Finally, I dedicate a whole other post to explain some of the painful lessons we
learned while introducing these improvements. A heads up, I will focus mainly on the Python Packaging Authorities
systems (pip, setuptools, so no conda or operating system-specific packagers).

An example project Link to heading
To tell this story, I need to explain how python package distribution works, how package installation worked in the
past, and how we hope it will work in the future. To have a concrete example of what to demonstrate, let me introduce my
example library: pugs. This library is reasonably simple: it generates a single package called pugs containing only
a single module called logic. The logic generates random quotes about pugs. Here’s a simple example structure of it
viewed as a source tree (also available under gaborbernat/pugs
):
pugs-project
├── README.rst
├── setup.cfg
├── setup.py
├── LICENSE.txt
├── src
│ └── pugs
│ ├── __init__.py
│ └── logic.py
├── tests
│ ├── test_init.py
│ └── test_logic.py
├── tox.ini
└── azure-pipelines.ymlWe have four distinct content type here:
What would it mean for our pugs package to be available on a user machine’s interpreter? Ideally, the user should be
able to import it and call functions from it once it starts up the interpreter:
- the business logic code (what’s inside the
srcfolder), - the test code (
testsfolder andtox.ini), - the packaging code and metadata (
setup.py,setup.cfg,LICENSE.txt,README.rst- note we use nowadays the de facto standard packaging tool setuptools ), - files helping with project management and maintenance:
- continuous-integration (
azure-pipelines.yml) - version control (
.git) - project management (for example, a potential
.githubfolder).
- continuous-integration (
Python 3.7.2 (v3.7.2:9a3ffc0492, Dec 24 2018, 02:44:43)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pugs
>>> pugs.do_tell()
"An enlightened pug knows how to make the best of whatever he has to work with - A Pug's Guide to Dating - Gemma Correll"
Python package availability Link to heading
How does Python knows what’s available or not? The short answer is it does not. Not upfront, at least, that is. Instead, it will try to load and see if it succeeds dynamically. From where does it load it? There are many possible locations, but in most cases, we are talking about loading it from a folder on the file system. Where is this folder? For a given module, one can print out the representation of the module to find out:
>>> import pugs
>>> pugs
<module 'pugs' from '/Users/bernat/Library/Python/3.7/lib/python/site-packages/pugs/__init__.py'>The folder under you’ll find it depends on:
- the type of the package it is (third-party or built-in/aka part of the standard library)
- if it’s globally or just for the current user available (see PEP-370 ),
- and if it’s a system python or a virtual environment.
Generally speaking, though, for a given python interpreter, one can find a list of possible directories by printing out
the sys.path variables content, for example, on my macOS:
>>> import sys
>>> print('\n'.join(sys.path))
/Library/Frameworks/Python.framework/Versions/3.7/lib/python37.zip
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload
/Users/bernat/Library/Python/3.7/lib/python/site-packages
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packagesFor third-party packages, it’s going to be some site-packages folder. Note in the above example how there’s a
system-wide and a user-specific instance of this. How do packages end up inside this folder? It must be put there by
some installer.
The following diagram displays how most of the time things go:
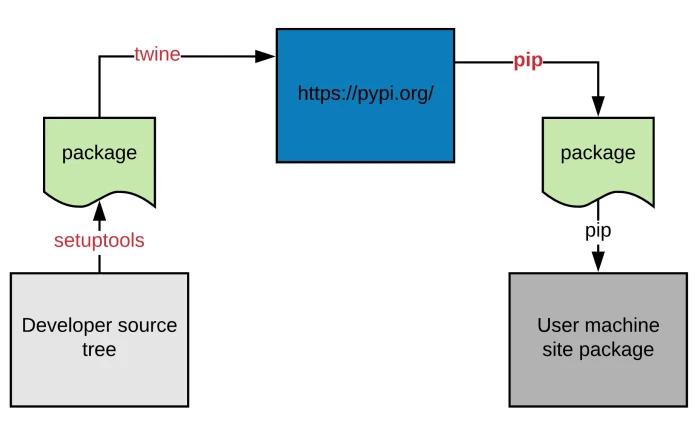
- The developer writes some python code inside a folder (referred to as the source tree).
- Some tool (such as
setuptools) then takes the source tree and packages it up for redistribution. - The generated package is uploaded via another tool (twine) to a central repository (usually https://pypi.org ) the end-user machine has access to.
- The end-user machine uses some installer that discovers, downloads, and installs the package in question. The
installation operation boils down by creating the correct directory structure and metadata inside the
site-packagesfolder.

Python package types Link to heading
A package during installation must generate at least two types of content to be put in the site package: a metadata
folder about the package contents the {package}-{version}.dist-info and the business logic files.
/Users/bernat/Library/Python/3.7/lib/python/site-packages/pugs
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-37.pyc
│ └── logic.cpython-37.pyc
└── logic.py/Users/bernat/Library/Python/3.7/lib/python/site-packages/pugs-0.0.1.dist-info
├── INSTALLER
├── LICENSE.txt
├── METADATA
├── RECORD
├── WHEEL
├── top_level.txt
└── zip-safeThe distribution info folder describes the package: what installer was used to put it there, what license the package has attached to it, what files were created as part of the installation process, what is the top-level python package, what entry points the package exposes and so on. A good description of each file can be found inside PEP-427 .
How do we get from our source tree to these two content types? We have two distinct paths in front of us:
- Generate this directory structure and metadata from our source tree, compress it into a single file, and publish it
to the central package repository. In this case, the installer has to download the package and extract it to the
site-packagesfolder. We refer to this type of package as awheelpackage. - Alternatively, you can create an archive containing the package source, build scripts and metadata required to
generate the installable directory structure, then upload that to the central repository. This is called a source
distribution or
sdist. In this case, the installer has a lot more work to do, extracts the archive, runs the builder, and only then copies it over.
The difference between the two options is mainly about where the package compile/build operation happens: the developers’ machine or the end-users machine. If it occurs on the developers’ side (such as wheels), the installation process is very lightweight. Everything has already been done on the developer machine side. The user machine side operation is just a simple download and decompress.
In our case, we used setuptools as our builder (the part that generates from the source tree the content to be put
inside the site-packages folder). Therefore, to perform the build operation on the user machine, we would need to ensure
that an appropriate version of setuptools is available on the user machine (if you’re using a feature from version
40.6.0 you must guarantee that the user has at least that version).
Another use case to consider is that Python offers access to C/C++ libraries from within Python (to get that extra performance where you need it). Packages that do so are referred to as C-extension packages, as they take advantage of the C-extension API CPython offers.
Such extensions to work though, need to C/C++ compile their functionality against both the C/C++ library they interact
with and the current Python interpreters C-API library. In these cases, the build operation involves calling a binary
compiler, not just metadata and folder structure generation as was the case with pure python packages (such as our
pugs library was).
If the build happens on the user machine, one needs to ensure that the correct libraries and compilers are also available at build time. This is now a much harder job, as these are platform-specific binaries distributed via the platform’s packaging tools. The lack or version miss-match of these libraries often triggers cryptic errors during the build, which leaves users frustrated and puzzled.
Therefore, if possible, always prefer packaging your package as a wheel. This will altogether avoid the problem of users not having all the correct build dependencies (both pure python types such as setuptools or binary ones as is the C/C++ compiler). Even if those build dependencies are easy to provision (such as in the case of pure python builders - e.g. setuptools) you can save install time by avoiding this step entirely.
That being said they are still two use cases that warrant providing source distributions (even when you provide a wheel):
- C-extension source distributions tend to be more auditable, as one can read the source code and thus offer greater transparency in what it offers: many big corporate environments prefer using these over wheels for this sole reason (they generally extend the rule to pure python wheels, mostly to avoid the need of categorizing what is pure python wheel and what is not).
- You might not be able to provide a wheel for every possible platform out there (especially true in case of c-extension packages), in this case, the source distribution may allow these platforms to generate the wheel themselves.
Conclusion Link to heading
The difference between a source tree, a source distribution, and a wheel:
- source tree - contains all project files available on the developers’ machine/repository (business logic, tests, packaging data, CI files, IDE files, SVC, etc.) - for example, see example project above.
- source distribution - contains code files required to build a wheel (business logic + packaging data + often also
the unit tests files to validate the build; notably lacks developer environment content such as CI/IDE/version control
files) - format:
pugs-0.0.1.tar.gz. - wheel - contains the package metadata and source files to be put into the
site-packagesfolder - format:pugs-0.0.1-py2.py3-none-any.whl.

[Read the next post of the series here](https://bernat.tech/posts/pep-517-518/) to determine what happens when we install a package. Thanks for reading!