One of the main selling points for Python is that it is dynamically-typed. There is no plan to change this.
Nevertheless, in September 2014 Guido van Rossum (Python
BDFL) created a python enhancement proposal
(PEP-484) to add type hints to Python. It has been released for general usage a
year later, in September 2015, as part of Python 3.5.0.
Twenty-five years into its existence now
there was a standard way to add type information to Python code. In this blog post, I’ll explore how the system matured,
how you can use it, and what’s next for type hints.
Disclaimer: throughout this blog post, you’ll see many seals and penguin pictures. The reason for this is mostly my admiration for these animals, and hey, nothing like some cute animals to help digest some tricky topics, not?
Why do we need this? Link to heading

What it was designed to do? Link to heading
First, let’s see why do we need type hints in Python. There are multiple advantages of this, and I’ll try to enumerate it in their order of importance:
1. Easier to reason about code Link to heading
Knowing the type of parameters makes it a lot easier to understand and maintain a codebase. For example, let’s assume you have a function. While we know the types of the parameters at the time of creating the function, a few months down the line, this is no longer the case. Having stated the types of all parameters and return types right beside the code can speed up significantly the time required to catch up with a code snippet. Always remember that code you read code a lot more often than you write it. Therefore you should optimize for ease of reading.
Having type hints informs you of what parameter types you need to pass on when calling a function and when you need to extend/modify the function tells you about the type of data you get both as input and output. For example, imagine the following the send request function,
def send_request(
request_data: Any,
headers: Optional[Dict[str, str]],
user_id: Optional[UserId] = None,
as_json: bool = True,
): ...
Just looking at the signature of this, I know that while the request_data could be anything, the headers content is
a dictionary of strings. The user information is optional (defaulting to None), or it needs to be whatever UserId
encodes it too. The contract for as_json is that it needs to be always a boolean value, being a flag essentially even
though the name might not suggest that at first.
The truth is many of us already understand that type of information is essential. However, in lack of better options until now, this was often mentioned inside the docstring. The type hint system moves this closer to the function interface and provides a well-defined way to declare complex type requirements. Building linters that can check these type hint constraints ensure that they never become out of date, granted that you run them after every code change.
2.Easier refactoring Link to heading
Type hints make it trivial to find where a given class is used when you’re trying to refactor your codebase. While many
IDEs already have some heuristic in place to achieve this. Type hints allow them to have 100% detection and accuracy
ratio. Generally offers a smoother and more accurate detection of how types run through your code. Remember, while
dynamic typing means any variable can become any of types, all your variables have at all time one and only one type.
The type system still is very much a core component of programming. Remember all the time you’ve used isinstance to
drive your application logic.
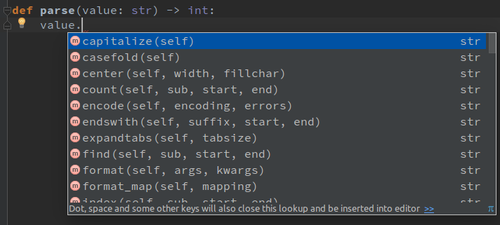
3. Easier to use libraries Link to heading
Having type hints mean IDEs can have a more accurate and smarter suggestion engine. Now when you invoke auto-complete, the IDE knows with complete confidence, what methods/attributes are available on an object. Furthermore, if the user tries to call something non-existent or passes arguments of an incorrect type, the IDE can instantly warn about it.
4. Type linters Link to heading
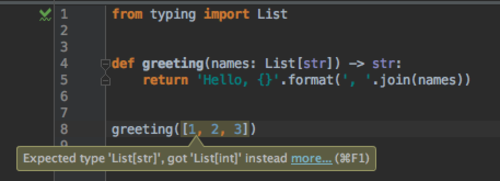
While the IDE suggesting incorrect argument types is excellent, an extension of this is to have a linter tool that makes
sure that type wise the logic of your application is sound. Running this tool can help you catch bugs early on (e.g., in
the example that follows, the input must be of type str, passing in None throws an exception):
def transform(arg):
return "transformed value {}".format(arg.upper())
# if arg would be type hinted as str the type linter could warn that this is an invalid call
transform(None)
While in this trivial case, some could argue that it’s easy to see the mismatch, remember this works in more complicated cases too, where such mismatches get harder and harder to see; such as nested function calls:
def construct(param=None):
return None if param is None else ""
def append(arg):
return arg + " appended"
transform(append(construct()))
While there are more and more linters out there, the reference implementation of the Python type checking is mypy. mypy is a Python command-line application, making it easy to integrate into a continuous integration pipeline.
5. Runtime data validation Link to heading
Type hints can be used to validate at runtime to ensure that the caller does not break the contract of methods. It is no longer needed to start your function with a long list of type asserts; instead, use a framework that re-uses type hints and automatically checks that they are meet before your business logic runs (for example, with pydantic):
from datetime import datetime
from typing import List
from pydantic import BaseModel, ValidationError
class User(BaseModel):
id: int
name = "John Doe"
signup_ts: datetime = None
friends: List[int] = []
external_data = {"id": "123", "signup_ts": "2017-06-01 12:22", "friends": [1, 2, 3]}
user = User(**external_data)
try:
User(signup_ts="broken", friends=[1, 2, "not number"])
except ValidationError as e:
print(e.json())
What it wasn’t designed to do? Link to heading
From the get-go, Guido clearly stated that type hints are not meant to be used for the following use cases (of course that does not mean that people do not have libraries/tools outside, which do just that - open source power for the win!):
1. No runtime type inference Link to heading
The runtime interpreter (CPython) does not try to deduce type information at runtime and perhaps validate arguments passed around based on that.
2. No performance tuning Link to heading
The runtime interpreter (CPython) does not use the type of information to optimize the generated byte-code for either security or performance. When executing a Python script type hints are treated just like comments; the interpreter discards it.
The key takeaway should be that type hints are designed to improve developer experience, not influencing how your script evaluates. It creates happy developers, not faster code!

What kind of type system? Link to heading
Python has gradual type hinting, meaning that whenever for a given function or variable, the type hint is not specified. We assume that it can have any type (that is, it remains a dynamically typed section). Use this to make your gradually codebase type-aware, one function, or variable at a time. It is possible to type hint:
- function arguments,
- function return values,
- variables.
Remember only type hinted code is type-checked! When you run the linter (e.g., mypy) on a type hinted code, you’ll get errors if there are type miss-matches:
# tests/test_magic_field.py
f = MagicField(name=1, MagicType.DEFAULT)
f.names()
This code will generate the following output:
bernat@uvm ~/python-magic (master●)$ mypy --ignore-missing-imports tests/test_magic_field.py
tests/test_magic_field.py:21: error: Argument 1 to "MagicField" has incompatible type "int";
expected "Union[str, bytes]"
tests/test_magic_field.py:22: error: "MagicField" has no attribute "names"; maybe "name" or "_name"?
Note we can detect both type incompatibility for the argument passed in and accesses to inexistent attributes on objects. The latter even suggests valid options available, making it easy to notice and fix typos.
How to add it Link to heading
Once you decide to add type hints, you’ll come to realize that you can add it in more than one way to the codebase. Let’s see what your options are.

1. Type annotations Link to heading
from typing import List
class A(object):
def __init__() -> None:
self.elements : List[int] = []
def add(element: int) -> None:
self.elements.append(element)
Type annotations is the straightforward way and is the one you’ll find mostly mentioned on the
typing documentation. It uses function annotations added to language
via PEP-3107 (Python 3.0+) and variable annotations via
PEP-526 (Python 3.6+). These allow you to use the : syntax to attach
information to variables and function arguments. The -> operator is used to attach information to the return value of
a function/method.
The upside of this method is that:
- It is the canonical way of doing this, which means it is the cleanest out of them all.
- Because the type of information is attached right alongside the code means you’ll have packaged this data out of the box.
The downside of it is that:
- It isn’t backward compatible. You need Python
3.6at least to use it. - It also forces you to import all of your type dependencies, even though they are not used at runtime at all.
- In the type hints, you can have compound types, for example,
List[int]. To construct these complex types, the interpreter does need to do some operations when first loading this file.
The last two points contradict the initial goal of the type system we enlisted before: handling all type information
basically as a comment during runtime. To resolve some of this contradiction Python 3.7 introduces
PEP-563 ~ postponed evaluation of annotations. Once you add the import of:
from __future__ import annotations
The interpreter will no longer construct these compound types. Once the interpreter parses the scripts syntax tree, it
identifies type hints and bypasses evaluating it, keeping it as raw strings. This mechanism allows for type hint
interpretation to happen where they need to: by the linter when it runs type checks. Once the mythical Python 4 comes
to life, this mechanism shall be the default behavior.
2. Type comments Link to heading
When the annotation syntax is not available, one can use the type comments:
from typing import List
class A(object):
def __init__():
# type: () -> None
self.elements = [] # type: List[int]
def add(element):
# type: (List[int]) -> None
self.elements.append(element)
Going down this path, we do get some benefits:
- Type comments work under any Python version. Although the typing library has been added to the standard library with
Python
3.5+is available as a PyPi package for Python2.7+. Moreover, because Python comments is a valid language feature under virtually any Python code, this allows you to type-hint any codebase at or above Python2.7. There are a few requirements: the type hint comment must be on the same or the next line where the function/variable definition is. It also starts with thetype:constant. - This solution also has packaging solved because comments are rarely stripped of your code once you stripped it. Packaging type hint information with your source code allows people using your library to use your type hint information to improve their developer experience.
But we also generate some new problems:
- The downside is that although the type of information is close to the arguments, it’s not right beside it, making the code a bit messier than otherwise would be. It must also be in a single line, causing issues if you have a long type of expression, and your codebase enforces line length limits.
- Another problem is that now the type hint information competes with other tools using these types of comment markers (e.g., suppressing other linter tools errors).
- Besides forcing you to import all of your type information, this leaves you in an even more precarious place. Now the
imported types are only used in the code, which leaves most linter tools to believe all those imports are unused. Were
you to allow them to remove it, and it does break your type linter. Note
pylintfixed this by moving its AST parser to a typed-ast parser, and is going to be released with version 2 just after Python3.7comes out.
To avoid having long lines of code as type hint, it’s possible to type hint arguments one by one via type comments, and then put in the line after only the return type annotation:
def add(
element, # type: List[int]
):
# type: (...) -> None
self.elements.append(element)
Let’s have a quick use look at how type comments can make your code messier. Below is a code snippet that swaps out two properties values inside a class. Fairly trivial:
@contextmanager
def swap_in_state(state, config, overrides):
old_config, old_overrides = state.config, state.overrides
state.config, state.overrides = config, overrides
yield old_config, old_overrides
state.config, state.overrides = old_config, old_overrides
First, you must add type hints. Because the type hint would be long-winded, you attach type hint argument by argument:
@contextmanager
def swap_in_state(
state, # type: State
config, # type: HasGetSetMutable
overrides, # type: Optional[HasGetSetMutable]
):
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
old_config, old_overrides = state.config, state.overrides
state.config, state.overrides = config, overrides
yield old_config, old_overrides
state.config, state.overrides = old_config, old_overrides
However, wait, you need to import your types used:
from typing import Generator, Tuple, Optional, Dict, Union, List
from magic import RunSate
HasGetSetMutable = Union[Dict, List]
@contextmanager
def swap_in_state(
state, # type: State
config, # type: HasGetSetMutable
overrides, # type: Optional[HasGetSetMutable]
):
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
old_config, old_overrides = state.config, state.overrides
state.config, state.overrides = config, overrides
yield old_config, old_overrides
state.config, state.overrides = old_config, old_overrides
Now formatting like this, the code causes some false positives in the static linter (e.g. pylint here), so you add a
few suppress comments for this:
from typing import Generator, Tuple, Optional, Dict, List
from magic import RunSate
HasGetSetMutable = Union[Dict, List] # pylint: disable=invalid-name
@contextmanager
def swap_in_state(
state, # type: State
config, # type: HasGetSetMutable
overrides, # type: Optional[HasGetSetMutable]
): # pylint: disable=bad-continuation
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
old_config, old_overrides = state.config, state.overrides
state.config, state.overrides = config, overrides
yield old_config, old_overrides
state.config, state.overrides = old_config, old_overrides
Now you’re done. Nevertheless, you made your six lines of code sixteen lines long. Yay, more code to maintain! Increasing your codebase only sounds good if you’re getting paid by the number line of code written, and your manager is complaining you’re not performing well enough.
3. Interface stub files Link to heading
This option allows you to keep your code as it is:
class A(object):
def __init__() -> None:
self.elements = []
def add(element):
self.elements.append(element)
and instead, add another file with pyi extension right beside it:
# a.pyi alongside a.py
from typing import List
class A(object):
elements = ... # type: List[int]
def __init__() -> None: ...
def add(element: int) -> None: ...
Interface files are not a new thing; C/C++ had it for decades now. Because Python is an interpreted language, it does not need it usually, however as every problem in computer science can be solved by adding a new level of indirection, we can add it to store the type of information.
The upside of this is that:
- You don’t need to modify the source code; works under any Python version as the interpreter never touches these.
- Inside the stub files, you can use the latest syntax (e.g., type annotations) because these are never looked at during your application’s execution. Because you do not touch your source code, you cannot introduce bugs by adding type hints, nor can you add conflict with other linter tools.
- It is a well-tested design; the
typeshedproject uses it to type hint the entire standard library, plus some other popular libraries such asrequests,yaml,dateutiland so on. It can provide type information for source code that you do not own or cannot change easily.
Now there are also some hefty penalties to pay:
- You just duplicated your codebase, as every function now has two definitions (note you don’t need to replicate your
body or default arguments, the
...- ellipsis - is used as a placeholder for these). - Now, you have some extra files that need to be packaged and shipped with your code.
- It’s impossible to annotate contents inside functions (this means both methods inside methods and local variables).
- There is no check that your implementation file matches your stub’s signature (furthermore, IDEs always use the stub definition).
- However, the heaviest penalty is that you cannot type check the code you’re type hinting via a stub. Stub file type hints were designed to be used to type-check code that uses the library. But not too type check the codebase itself what your type hinting.
The last two drawback makes it incredibly hard to check that the type hinted codebase via a stub file is in sync or not. In this current form, type stubs are a way to provide type hints to your users, but not for yourself, and are incredibly hard to maintain. To fix these, I’ve taken up the task of merging stub files with source files inside mypy; in theory, fix both problems - you can follow on its progress under python/mypy ~ issue 5208.
4. Docstrings Link to heading
It is possible to add type information into docstrings too. Even though this is not part of Python’s type-hint framework, it is supported by most mainstream IDEs. They are mostly the legacy way of doing this.
On the plus side:
- Works under any Python version. It was defined back in PEP-257. It does not clash with other linter tools, as most of these do not check the docstrings but usually resume just inspecting the other code sections instead.
However, it has serious flaws in the form of:
- There is no standard way to specify complex type hints (for example, either
intorbool). PyCharm has it’s the proprietary way but Sphinx, for example, uses a different method. T- Docstring types do not clash with other linter tools. - Requires changing the documentation, and it is hard to keep accurate/up to date as there is no tool to check it’s validity.
- Docstring types do not play well with type hinted code. If both type annotations and docstrings are specified, which takes precedence over which?
What to add? Link to heading

Let’s dive into the specifics, though. For an exhaustive list of what type of information you can add, please see the official documentation. Here I’ll do a quick 3-minute overview for you to get the idea of it. There are two types of type categories: nominal types and duck types (protocols).
1. Nominal type Link to heading
Nominal types are types that have a name to it within the Python interpreter. For example all builtin types (int,
boolean, float, type, object etc). Then we have the generic types which mostly manifest in form of the
containers:
t: Tuple[int, float] = 0, 1.2
d: Dict[str, int] = {"a": 1, "b": 2}
d: MutableMapping[str, int] = {"a": 1, "b": 2}
l: List[int] = [1, 2, 3]
i: Iterable[Text] = ["1", "2", "3"]
For compound types, it can become cumbersome to keep writing it again and again, so the system allows you to alias types, via:
OptFList = Optional[List[float]]
One can even elevate builtin types to represent their own type, which can be useful to avoid errors where for example you pass in two arguments with the same type in the wrong order to a function:
UserId = NewType("UserId", int)
user_id = UserId(524313)
count = 1
call_with_user_id_n_times(user_id, count)
For namedtuple you can attach your type information directly (note the strong resemblance to a
data class from Python 3.7+ or the great
attrs library):
class Employee(NamedTuple):
name: str
id: int
You have the composing types of one of and optional of:
Union[None, int, str] # one of
Optional[float] # either None or float
You can even type hint your callback functions:
# syntax is Callable[[Arg1Type, Arg2Type], ReturnType]
def feeder(get_next_item: Callable[[], str]) -> None:
One can define it’s own generic containers by using the TypeVar construction:
T = TypeVar('T')
class Magic(Generic[T]):
def __init__(self, value: T) -> None:
self.value : T = value
def square_values(vars: Iterable[Magic[int]]) -> None:
v.value = v.value * v.value
Finally, disable type checking wherever it’s not needed by using the Any type hint:
def foo(item: Any) -> int:
item.bar()
2. Duck types - protocols Link to heading
In this case, instead of having an actual type, one can be more Pythonic and go with the theorem that if it quacks like a duck, and acts like a duck, then most definitely for all intended purposes, it is a duck. In this case, you define what operations and attributes you expect on objects instead of explicitly stating their types. The grounds of this were laid down in PEP-544 ~ Protocols.
KEY = TypeVar("KEY", contravariant=true)
# this is a protocol having a generic type as an argument
# it has a class variable of type var, and a getter with the same key type
class MagicGetter(Protocol[KEY], Sized):
var: KEY
def __getitem__(self, item: KEY) -> int: ...
def func_int(param: MagicGetter[int]) -> int:
return param["a"] * 2
def func_str(param: MagicGetter[str]) -> str:
return "{}".format(param["a"])
Gotchas Link to heading
Once you start adding type hints to a codebase, watch out that sometimes you may experience some oddities. During these moments, you might have the *what the hell** expression of the following seal:

In this section, I’ll try to present a few of these to give you a heads up on what kind of oddities you may run into while adding type information to your codebase.
1. str difference in between Python 2/3 Link to heading
Here’s a quick implementation of the repr dunder method for a class:
from __future__ import unicode_literals
class A(object):
def __repr__(self) -> str:
return "A({})".format(self.full_name)
This code has a bug in it. While this is correct under Python 3, it is not under Python 2 (because Python 2 expects to
return bytes from repr. However, the unicode_literals import makes the returned value of type unicode). Having
the from future import in place means it’s not possible to write a repr that satisfies the type requirements for both
Python 2 and 3. You need to add runtime logic to do the right thing:
from __future__ import unicode_literals
class A(object):
def __repr__(self) -> str:
res = "A({})".format(self.full_name)
if sys.version_info > (3, 0):
# noinspection PyTypeChecker
return res
# noinspection PyTypeChecker
return res.encode("utf-8")
To fight the IDE to accept this form, you need to add a few linter comments, making this code ever so complicated to read. More importantly, now you have an extra runtime check forced to your type checker.
2. Multiple return types Link to heading
Imagine you want to write a function that multiplies either a string or an int by two. The first take on this would be:
def magic(i: Union[str, int]) -> Union[str, int]:
return i * 2
Your input is either str or int, and your return value accordingly is also either str or int. However, if you do
it like so, you’re telling the type hint that it really can be either of for both types of inputs. Therefore on the call
side, you need to assert the type your calling with:
def other_func() -> int:
result = magic(2)
assert isinstance(result, int)
return result
This inconvenience may determine some people to avoid the call side hassle by making the return value Any. However,
there’s a better solution. The type hint system allows you to define overloads. Overloads express that for a given input
type, and only a given output type is returned. So, in this case:
from typing import overload
@overload
def magic(i: int) -> int:
pass
@overload
def magic(i: str) -> str:
pass
def magic(i: Union[int, str]) -> Union[int, str]:
return i * 2
def other_func() -> int:
result = magic(2)
return result
There is a downside to this, though. Now your static linter tool is complaining that you’re redefining functions with
the the same name; this is a false positive so add the static linter disable comment mark
(# pylint: disable=function-redefined ).
3. Type lookup Link to heading
Imagine you have a class that allows representing the contained data as multiple types or that has fields of the different type. You want the user to have a quick and easy way to refer to them, so you add a function, having a built-in types name:
class A(object):
def float(self):
# type: () -> float
return 1.0
Once you run the linter, you’ll see:
test.py:3: error: Invalid type "test.A.float"
One might ask, at this point, what the hell? I’ve defined the return value as float, not as test.A.float. This
obscure error is that the type hinter resolves types by evaluating each scope outbound from the definition location.
Once it finds a name match, it stops. The first level where it looks is within class A where it finds a float (a
function that is) and substitutes that float in.
Now the solution to not run into this issue is to explicitly define that we don’t just want any float, but that we
want the builtin.float:
if typing.TYPE_CHECKING:
import builtins
class A(object):
def float(self):
# type: () -> builtins.float
return 1.0
Note that to do this, you also need to import builtins, and to avoid this causing issues at runtime, you can guard it
with the typing.TYPE_CHECKING flag, which is true only during the type linter evaluation, always false otherwise.
4. Contra-variant argument Link to heading
Examine the following use case. You define an abstract base class that contains everyday operations. Then you have specific classes that handle one type and one type only. You control the creation of the classes, which ensures the correct type is passed, and the base is abstract, so this seems an agreeable design:
from abc import ABCMeta, abstractmethod
from typing import Union
class A(metaclass=ABCMeta):
@abstractmethod
def func(self, key): # type: (Union[int, str]) -> str
raise NotImplementedError
class B(A):
def func(self, key): # type: (int) -> str
return str(key)
class C(A):
def func(self, key): # type: (str) -> str
return key
However, once you run a type linter check on this, you’ll find:
test.py:12: error: Argument 1 of "func" incompatible with supertype "A"
test.py:17: error: Argument 1 of "func" incompatible with supertype "A"
The reason for this is that arguments to classes are contra-variant. This translates in on scientific terms in your derived class you must handle all types from your parents. However, you may add additional types too. That is even in the function arguments; you can only extend what you cover, but not to constrain it in any way:
from abc import ABCMeta, abstractmethod
from typing import Union
class A(metaclass=ABCMeta):
@abstractmethod
def func(self, key): # type: (Union[int, str]) -> str
raise NotImplementedError
class B(A):
def func(self, key): # type: (Union[int, str, bool]) -> str
return str(key)
class C(A):
def func(self, key): # type: (Union[int, str, List]) -> str
return key
5. Compatibility Link to heading
See if you can spot the error in the following code snippet:
class A:
@classmethod
def magic(cls, a: int) -> "A":
return cls()
class B(A):
@classmethod
def magic(cls, a: int, b: bool) -> "B":
return cls()
If you did not manage yet, consider what will happen if you write the following script:
from typing import List, Type
elements: List[Type[A]] = [A, B]
print([e.magic(1) for e in elements])
Were you to try to run it this would fail with the following runtime error:
print( [e.magic(1) for e in elements])
TypeError: magic() missing 1 required positional argument: 'b'
The reason being that B is a subtype of A. Therefore it can go into a container of A types (because it extends it
to do more than A). However, the class method definition for B breaks this contract, it can no longer call magic
with just one argument. Moreover, the type linter would fail to point out only this:
test.py:9: error: Signature of "magic" incompatible with supertype "A"
A quick and easy fix for this is to make sure B.magic does work with one argument by making the second optional for
example. Now take what we learned to take a look at the following:
class A:
def __init__(self, a: int) -> None:
pass
class B(A):
def __init__(self, a: int, b: bool) -> None:
super().__init__(a)
What do you think will happen here? Note we moved class methods into constructors and made no other change, so our the script also needs just a slight modification:
from typing import List, Type
elements: List[Type[A]] = [A, B]
print([e(1) for e in elements])
Here’s the runtime error, being mostly the same, just now complaining about __init__ instead of magic:
print( [e(1) for e in elements])
TypeError: __init__() missing 1 required positional argument: 'b'
So what do you think mypy will say? Were you to run it; you’ll find that mypy chooses to stay silent. Yes, it will mark
this as correct, even though at runtime, it fails. The mypy creators said that they found too common of type miss-match
to prohibit incompatible __init__ and __new__.
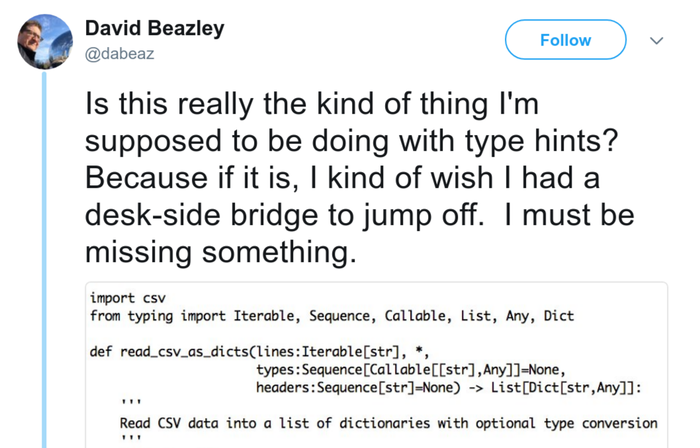
When you hit the wall Link to heading
So, in conclusion, watch out. Type hints sometimes cause strange warnings, which brings out the following feelings summarized in a tweet:
Remember you have some tools at hand that help you discover, understand and perhaps handle these edge cases:
- use
reveal_typeto see inferred typea = [4] reveal_type(a) # -> error: Revealed type is 'builtins.list[builtins.int*]' - use
castto force a given type:from typing import List, cast a = [4] b = cast(List[int], a) # passes fine c = cast(List[str], a) # type: List[str] # passes fine (no runtime check) reveal_type(c) # -> error: Revealed type is 'builtins.list[builtins.str]' - use the type ignore marker to disable an error in a line:
x = confusing_function() # type: ignore # see mypy/issues/1167 - ask the community; expose a minimal reproducible version of the problem under the python/typing community (the Gitter chat is no longer active).
Tools Link to heading
Here’s a non-exhaustive list of tools built around the type hint system.
type checkers Link to heading
Use these tools to check against type safety inside your library or application:
mypy- Python (the reference type linting tool)pyre- Facebook - Python 3 only, but faster than mypy. An interesting use case of this is the ability to do taint/security code analysis with it - see Pieter Hooimeijer - Types, Deeper Static Analysis, and you.pytype- Google.
type annotation generators Link to heading
When you want to add type annotations to an existing codebase, use these to automate the boring part:
mypy stubgencommand line (see)pyannotate- Dropbox - use your tests to generate type information.monkeytype- Instagram. Fun fact: Instagram uses to run it in their production system: it’s triggered once for every million cal (makes the code run five times slower, but once every million calls makes it not that noticeable).
runtime code evaluator Link to heading
Use these tools to check at runtime if the input arguments to your function/method are of the correct type or not:
Documentation enrichment - merge docstrings and type hints Link to heading
In the first part of this blog article, we mentioned that historically people have already stored type information inside docstrings. This is because your type of data is part of your contract. You do want to have type information for your library inside the documentation. So the question remains, given that you did not choose to use docstrings as the primary type of information storage system, how can you still have them in the docstrings for your documentation?
The answer varies depending on the tool you’re using to generate that documentation. However, I’m going to present here an option by using the most popular tool and format in Python: Sphinx and HTML.
Having type information explicitly stated in both the type hints and the docstring is the sure way of eventually having conflicts between them. You can count on someone at some point is going to update in one place but not in the other. Therefore let’s strip all type data from the docstring and have it only as type hints. Now, all we need to do is at documentation build time, fetch it from the type hints and insert it into the documentation.
In Sphinx, you can achieve this by having a plugin. The most popular already made version of this is
agronholm/sphinx-autodoc-typehints. This tool does two
things:
- first, for each function/variable to be documented, it fetches the type hint information;
- then, it transforms the Python types into a docstring representation (this involves recursively unwrapping all the nested type classes, and replacing the type with its string representation);
- finally, appending to the correct parameter into the docstring.
For example Any maps to py:data:`~typing.Any`. Things can get even more complicated for compound types such as
Mapping[str, bool] needs to be translated for example too
:class:`~typing.Mapping`\\[:class:`str`, :class:`bool`]. Getting the translation here right (e.g. having class
or data namespace) is essential so that the intersphinx plugin will work correctly (a plugin that links types
directly to their respective Python standard library documentation link).
In order to use it one needs to install it via pip install sphinx-autodoc-types>=2.1.1 and then enable in inside the
conf.py file:
# conf.py
extensions = ["sphinx_autodoc_typehints"]
That’s it all. An example use case of this is RookieGameDevs/revived documentation. For example, given the following source code:
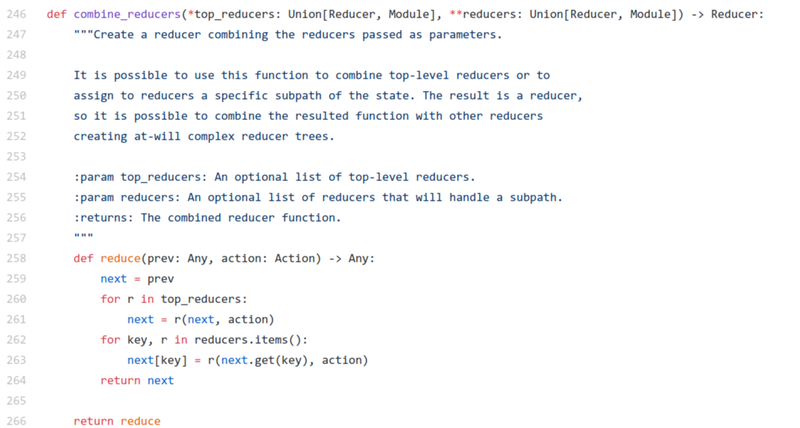
You can get the following output:

Conclusion Link to heading
So at the end of this long blog post, you may ask: is it worth using type hints, or when should one use them? I think type hinting is at the end of the day virtually the same as your unit tests, just expressed differently in code. They provide a standard (and re-usable for other goals) way to test the input and output types of your codebase.
Therefore, type hints should be used whenever the unit test is worth writing. This can be even just ten lines of code if you need to maintain it later. Similarly, you should start adding type hints whenever you start writing unit tests. The only place when I would not add them is when I don’t write unit tests, such REPL lines, or throw away one-time usage scripts.
Remember that, similar to unit tests, while it does makes your codebase contain an extra number of lines, at the end of the day, all the code you add is code that is automatically checked and enforced to be correct. It acts as a safety net to ensure that things keep working when you change things around later on, so probably worth paying this extra cost.
